- DATE:
- AUTHOR:
- The Launchable Product Team
Observe Predictive Test Selection behavior before you roll out Launchable
Sometimes teams want to observe the potential impact and behavior of running Predictive Test Selection subsets in a real environment before they enable subsetting for all test sessions. In other words, they want to measure subsets' real world efficacy against the Confidence curve shown on the "Simulate" page.
For example, a workspace's Confidence curve might state that Launchable can find 90% of failing runs in only 40% of the time, for example. Some teams might want to verify that statistic in real life.
Well, we now have a solution to that problem. Behold observation mode!
To enable observation mode, just add --observation to the launchable subset command you added to your pipeline after following Requesting and running a subset of tests:
launchable subset \
--observation
--target 30%
... [other options]When observation mode is enabled for a test session, the output of each launchable subset command made against that test session will always include all tests, but the recorded results will be presented separately so you can compare running the subset against running the full suite.
Because you marked the session as an observation session, Launchable can analyze what would have happened if you had actually run a subset of tests, such as whether the subset would have caught a failing session, and how much time you could have saved by running only the subset of tests:
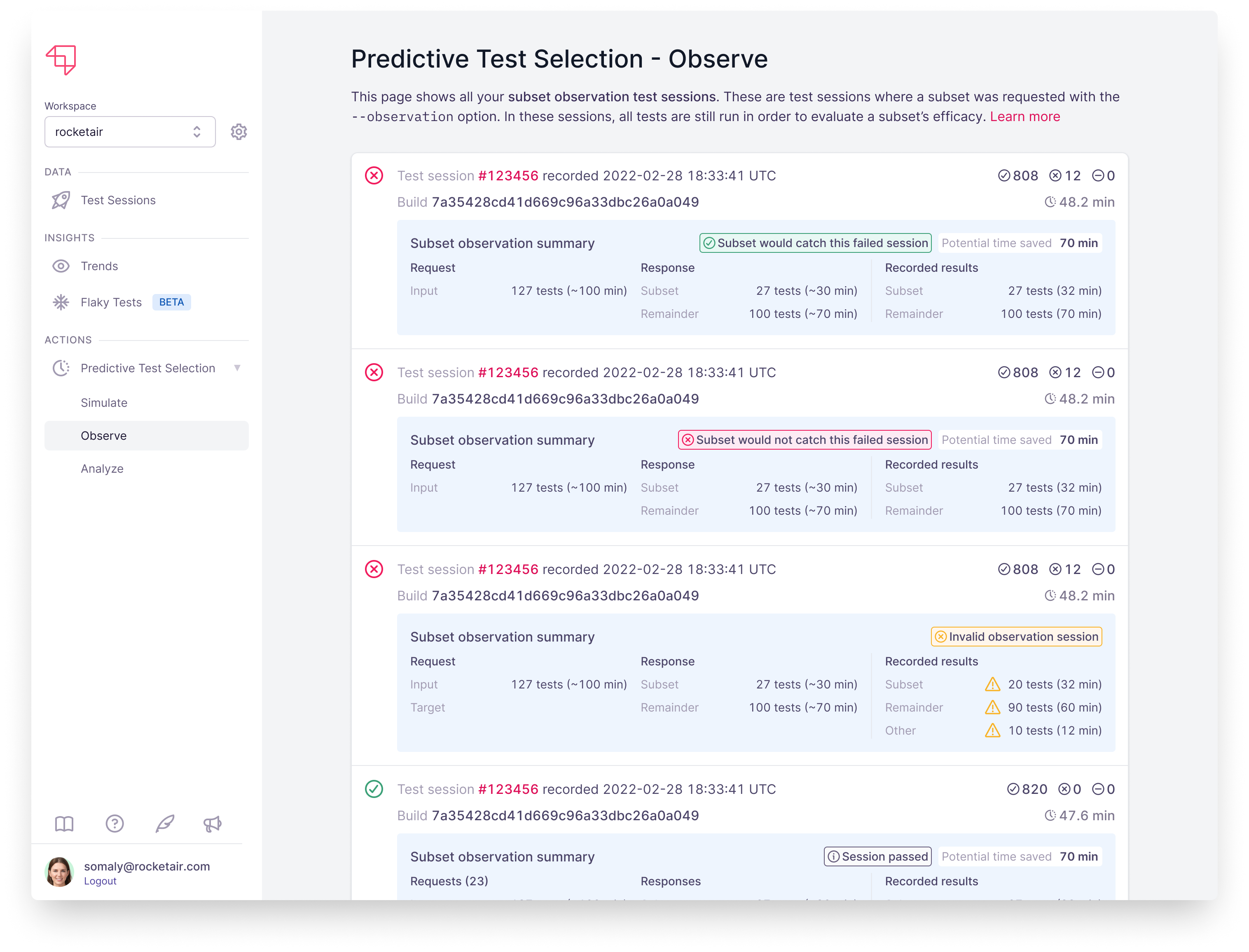
You can learn more about observation mode here: https://docs.launchableinc.com/features/predictive-test-selection/observing-subset-behavior
Or reach out to your customer success manager for more info.